La redécentralisation d'Internet : une question de pouvoir et littératie
Cet article propose de présenter en quoi il y a un enjeu réel à se préoccuper de nos infrastructures matérielles et logicielles à l'heure où nos usages sont totalement intégrés au réseau ; et ensuite de montrer que des initiatives associatives ou entrepreneuriales rendent aujourd'hui certaines alternatives accessibles à chacun.
Il ne s'agit pas simplement de protéger ses données ou de la liberté d'expression, il s'agit plus fondamentalement encore de comprendre le monde dans lequel nous vivons.
Le temps passé en compagnie de nos objets numériques est de plus en plus conséquent. Nous dépossédons pourtant de plus en plus de notre pouvoir sur les applications d'Internet, de plus en plus concentré au sein d'une poignée acteurs qui échappent au contrôle politique. Nous nous dépossédons également de plus en plus la compréhension de ces applications dont les interfaces nous éloignent de la technologie, pour nous simplifier l'existence, pour notre confort. Ne pas avoir ni à contrôler ni à comprendre est confortable.
La relation entre savoir et pouvoir a été articulée par Jack Goody[1] autour du concept de littératie, ce que l'on peut résumer par : celui qui maîtrise les supports de la connaissance possède le pouvoir.
Merci Google !
Internet, une ZAD
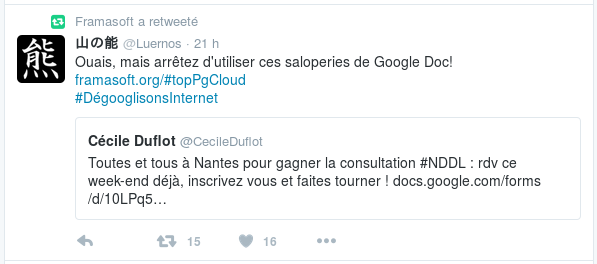
Pourquoi l'association Framasoft retweete-t-elle ces propos insultants à l'égard de Google Doc ? Pourquoi pense-t-elle que les opposants au projet Notre-Dame-Des-Landes devraient éviter de supporter les initiatives du géant Google ? Internet serait-il aussi une Zone À Défendre[2] ? Quel rapport aussi direct y-aurait-il entre les mouvements anti-capitalistes et la campagne Dégooglisons Internet de Framasoft ?
De LVMH à Google
L'excellent film Merci Patron ! réalisé par François Ruffin (2016)[3] est d'abord un film drôle et éloquent sur la lutte des classes au XXIème siècle (Lordon, 2016[4]). Je le mobilise en introduction de cet article car il rappelle, à travers l'exemple d'un empire comme LVMH, la concentration des pouvoirs dont dispose les grands groupes industriels. Pouvoirs économique, médiatique, même policier, de faire et défaire les vies, de configurer les territoires, de faire les politiques, de se soustraire aux lois. Ils échappent au contrôle démocratique, supplantent même la république, internationaux, globaux, en dehors, au dessus.
Il commence à être convenu d'admettre le caractère nuisible de cette forme de capitalisme, en revanche on peine à accepter qu'un Google puisse être, ou devenir, aussi « evil »
(le slogan de Google est don't be evil, ne soyez pas malveillants selon Wikipédia, que je traduirais plutôt par ne soyez malfaisants). Et pour cause, là où LVMH propose des produits hors de prix réservés à une élite, licencie, délocalise, impose une image négative et old school, emploie des barbouzes, et entretient des relations incestueuses avec les pouvoirs traditionnels ; Google est une entreprise cool, qui offre des services gratuits, qui crée des emplois enviables, des montres et des voitures qui parlent, des intelligences artificielles, des robots bienveillants. LVMH c'est le XIXème, c'est Zola, Google c'est le XXIème, c'est Asimov. Bien sûr il y a les emplois Amazon (Malet, 2013), la connivence de Google et de la NSA (Mediapart, 2014)[5], les censures de Facebook (Ducros, 2011)[6], les stratégies de fermetures logicielles et matérielles de Microsoft et d'Apple, les données personnelles, les licences léonines, les pratiques systématiques de défiscalisation...
Mais en quelque sorte, le monde n'est pas parfait, c'est la vie... et puis Windows on est tellement habitué, un Mac c'est si beau, un Google Doc si pratique, un compte Facebook si indispensable. Qui parle d'acheter un livre ailleurs que sur Amazon ?
Une question de pouvoir : alternative et indépendance
Alors quel est le problème avec ces « saloperies (sic) »
de Google Doc ? Le problème est celui de la concentration des pouvoirs et de son absence de contrôle par les citoyens.
Tandis que les LVMH peuvent arbitrairement configurer les territoires physiques, les GAFAM[7] peuvent arbitrairement reconfigurer les territoires d'internet, c'est à dire fondamentalement, la structure et le contrôle de l'information. Le moteur de recherche Google hiérarchise l'accès à l'information, créant de facto un Web accessible et un Web dit profond, non ou mal indexé. Facebook vise à remplacer le web et le mail, devenant pour certains utilisateurs la porte d'accès unique à l'information et aux échanges électroniques. Amazon fait de même avec le commerce électronique, et livre en une heure n'importe quel produit à Paris (Champeau, 2016)[8]. Apple, via son store, décide de ce qu'il est admis de consulter sur un terminal mobile, ni trop chaud par la censure des applications, ni trop froid par la suprématie de la popularité. Ces reconfigurations touchent progressivement à la structure même d'internet, « 0,008 % des réseaux concentrent plus de 50 % du trafic en France » (Champeau, 2015)[9].
L'enjeu est donc de conserver une forme de contrôle par les utilisateurs, par les citoyens, de la configuration des pouvoirs sur internet. La question est de savoir ce que peut bien faire chacun à son niveau, face à la puissance technologique et financière des GAFAM, dont les chiffres d'affaires ont rejoint ceux des plus puissantes entreprises brick and mortar - Google s'offrant même la première place mondiale de la capitalisation boursière en 2016 - et dont les liquidités leur permettent de racheter toutes les autres start-up du domaine des technologies de l'information.
La tête dans les nuages, les pieds sur terre
« Demander à des gens d'utiliser un logiciel moche plutôt que celui de d'habitude ça risque de pas très bien marcher. »
répond Nephos au Tweet de @Luernos.
Plus inattendu que la critique des empires privés internationaux, Merci Patron ! en a aussi montré une certaine vulnérabilité, LVMH ayant été facilement secoué par une poignée d'activistes "régionaux". La résistance aux empires du Web s'organise aussi ; la plus impressionnante d'entre elles, en France au moins, est la campagne de Framasoft Degooglisons Internet. Son objectif est de proposer des alternatives opérationnelles aux outils des « multinationales tentaculaires »
du Web. Le travail réalisé est déjà conséquent, et permet réellement de réduire progressivement sa dépendance.
Mais l'objectif de Framasoft n'étant pas de centraliser à son tour, son action est avant tout pédagogique : il existe des outils libres qui permettent de s'autonomiser. Il est possible de s'en emparer, il est possible pour des associations modestes d'héberger de services ouverts, il est même possible de s'auto-héberger, c'est à dire de gérer ses propres services pour ses propres besoins et pour ceux de ses proches. L'informatique moderne permet cela. Il y a 40 ans se développait l'ordinateur personnel, le PC, pour Personal Computer. C'était l'occasion pour chacun de s'initier à l'informatique et de prendre le contrôle des applications bureautiques. C'est aujourd'hui l'heure d'un PC d'un nouveau genre, le Personnal Cloud. Et c'est l'occasion pour chacun de prendre le contrôle des applications en réseaux.
Une question de littératie : comprendre, faire, choisir
Il s'agit de comprendre de quoi l'on parle.
Il s'agit de faire, c'est à dire d'accepter de passer du temps, pour apprendre, bricoler, échanger.
Il s'agira ensuite de choisir, en connaissance de cause, cette fois.
Si de la dégooglisation trouve sa place sur ce site, c'est que, au delà de la question du pouvoir, se trouve une vraie question de littératie (si tant est que ces questions puissent être séparées).
Les applications Web que nous utilisons, si pratiques, si rapides, si belles, nous coupent de l'appréhension, et de la compréhension d'un monde numérique, dans lequel nous vivons pourtant de plus en plus immergé. Il ne s'agit pas simplement de protéger ses données de la NSA ou du ciblage commercial, pas seulement de la liberté d'expression sur internet, il s'agit, à mon sens, plus fondamentalement encore de comprendre le monde dans lequel nous vivons.
La décentralisation d'internet : perspectives historique et technique
« “The web is already decentralized,” Mr. Berners-Lee said. “The problem is the dominance of one search engine, one big social network, one Twitter for microblogging. We don't have a technology problem, we have a social problem.” (Hardy, 2016) »
La décentralisation comme fondement historique d'internet
Internet a à l'origine été conçu explicitement comme un système décentralisé : l'enjeu était de construire un réseau invulnérable, c'est à dire qui ne puisse ni être contrôlé (par un gouvernement ennemi) ni être détruit (par une attaque nucléaire). La seule solution à un tel problème était la décentralisation : personne ne possède internet personne ne contrôle internet, personne ne décide qui peut s'y connecter ni ce qu'il peut faire une fois connecté.
Éléments d'histoire d'internet
« Au commencement était internet, un réseau de réseaux qui était bête, pour que chacun d'entre nous puisse décider ce qu'il veut en faire. (Aigrain, 2013[10]) »
Internet est né du projet Arpanet (financé par la recherche militaire étasunienne), qui relie en 1969 quatre universités de telle façon que le réseau pouvait résister à la défaillance d'un ou plusieurs nœuds : il n'y avait pas de machine centrale pour gérer la communication. En 1983, le protocole TCP/IP est adopté, c'est encore l'actuel protocole de communication[11] entre les ordinateurs sur internet. Il permet de découper l'information en paquets et à ces paquets d'être transportés sur le réseau par des routeurs[12].
La première application d'internet est le mail en 1972, il permet à des ordinateur de s'échanger et de stocker des messages via internet. Le World Wide Web (WWW, ou web) est inventé en 1991 par Tim Berners-Lee au CERN, en Europe, alors qu'internet est devenu international. Il permet de stocker des contenus (les pages web) sur des ordinateurs (les serveurs web), et à d'autres ordinateurs de lire ces contenus à distance avec un navigateur web (le premier navigateur grand public est NCSA Mosaic, puis Netscape Navigator qui deviendra Mozilla Firefox).
On trouvera une histoire-géographie de la création d'internet sur vox.com (Lee, 2014[13]).
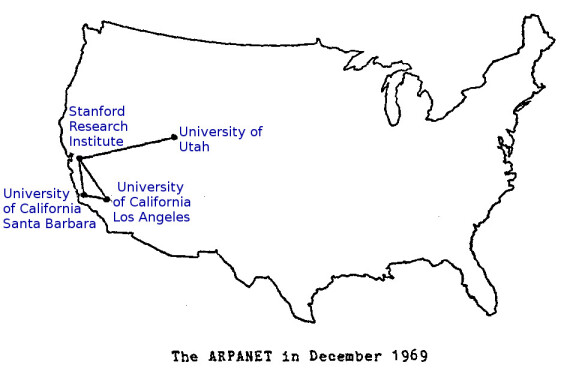
Éléments de géographie d'internet

Description d'internet
Internet, c'est fondamentalement :
des ordinateurs (ordinateurs personnels, serveurs spécialisés, terminaux mobiles, routeurs[12]...) ;
des liaisons entres ces ordinateurs (câbles réseau, fils téléphoniques, fibres optiques, ondes wifi...) ;
des protocoles de communication[11], c'est à dire des moyens pour les ordinateurs d'échanger de l'information ;
des applications, dont les plus utilisées aujourd'hui sont le web pour publier de l'information, le mail pour échanger des messages privés, mais aussi la messagerie instantanée ou le partage de fichier pair-à-pair.
Rappel : internet, le web, le mail...
Le développement d'internet ayant été concrétisé par ses applications, on a parfois tendance à confondre celui-ci avec celles-là ou à employer internet à la place d'une de ses applications par métonymie (notamment internet pour le web). Le web (la mise à disposition et l'accès à des pages web) n'est qu'une application sur internet. Le mail en est une autre.
La décentralisation comme fondement technique d'internet
Internet n'est pas une architecture totalement distribuée, c'est à dire dans laquelle tous les ordinateurs peuvent communiquer avec tous les autres directement. En effet, les ordinateurs ne sont pas reliés directement entre eux... sinon il faudrait beaucoup de fils.
C'est une architecture décentralisée, c'est à dire qu'il existe de nombreux centres reliés les uns aux autres : chaque centre est un réseau dirigé par un routeur[12] (c'est pourquoi on dit qu'internet est un réseau de réseaux). Un routeur est un ordinateur qui sait distribuer l'information sur son propre réseau quand elle lui est destinée, ou la renvoyer à d'autres routeurs sinon.
Dans un réseau domestique, le routeur est la box, c'est à lui que chaque ordinateur du réseau domestique (PC, téléphone, frigo connecté...) s'adresse, et c'est lui qui redistribue les messages entre les ordinateurs. Pour les accès à d'autres ordinateurs, le routeur box s'adresse au routeur du FAI[15] qui distribue les messages à d'autres routeurs et ainsi de suite.
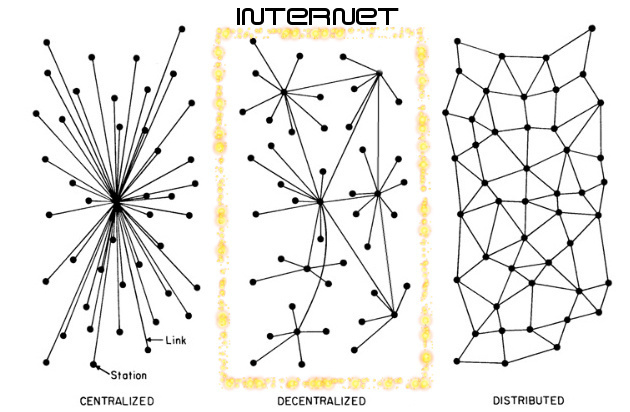
Points névralgiques et notion de neutralité d'internet
Dans la structure moderne d'internet, les particuliers dépendent donc de leur FAI[15] pour accéder à internet. Puisqu'il maîtrise les routeurs, et notamment la box qui se trouve dans la maison, le FAI maîtrise le flux d'information. Il peut en particulier décider de lire les messages qu'il fait transiter (pour éliminer du SPAM, pour espionner), il peut décider de ne pas connecter certains ordinateurs (dont le contenu est illégal, dont le contenu est concurrent, dont le contenu est "immoral"), il peut décider de régler le débit d'information (en fonction de la consommation de chacun, du prix qu'il paye, d'avec qui il communique).
Par exemple Free s'est illustré à deux reprises en 2012 et 2013 : en bridant le trafic en provenance de Youtube, faute de trouver un accord commercial avec son propriétaire Google ; et en filtrant les publicités au niveau de la Freebox. Dans le fond, Free posait des questions intéressantes : le financement des infrastructures par ceux qui les mobilisent et en profite le plus (la vidéo, Google...) ou le développement anarchique de la publicité sur les pages web. On peut d'ailleurs considérer que Free a fait avancer le débat sur ces deux points. Mais sur la forme, Free a utilisé de façon autoritaire son pouvoir de FAI, en modifiant les règles du trafic sur internet.
Cela s'oppose à un principe fondamental dit de neutralité d'internet[17] (ou du Net), défendu en France notamment par l'association La Quadrature Du Net. Ce principe de neutralité a jusqu'ici été relativement préservé, mais certains acteurs souhaitent le remettre en cause pour des raisons économiques (contrôler les flux) ou gouvernementales (contrôler l'information).
L'exemple des serveurs DNS
Les ordinateurs reliés à internet dispose d'une adresse (dite adresse IP[18]), qui sert à identifier les parties prenantes des échanges. Par exemple l'adresse 193.51.224.177 désigne un ordinateur de Google qui permet d'effectuer des recherches sur le web. Mais les êtres humains n'étant pas très à l'aise avec de telles suites de chiffres, pour leur confort, ils ont mis en place des noms de domaine, comme aswemay.fr, plus facile à retenir et ayant une fonction signifiante, comme une marque.
Ainsi, lorsque vous voulez faire une recherche (et tant que cet article ne vous a pas proposé d'alternative), vous tapez l'adresse google.fr dans votre navigateur, plutôt que 193.51.224.177 (c'est humain).
En fait, lorsque vous demandez l'adresse google.fr, votre ordinateur va interroger un serveur DNS (pour Domain Name System, système de noms de domaine), dont le rôle est de convertir le nom de domaine (google.fr) en adresse IP (193.51.224.177). Une fois récupérée l'adresse IP, votre ordinateur sait à quelle machine vous vouliez vous adresser et la communication s'enclenche. Il existe historiquement des serveurs DNS contrôlés par plusieurs organisations internationales (à dominante étasunienne). Il existe d'autres initiatives, comme OpenDNS, contrôlé par Cisco... et Google Public DNS proposé depuis 2009, pour « accélérer notre navigation sur internet »
(Korben, 2009[19]). Si on peut s'interroger sur cet argument, le coût en temps de la requête DNS dans le processus d'accès au contenu web étant marginal, on pourra en revanche mettre en lumière les enjeux que représentent la maîtrise des requêtes DNS : la connaissance et le contrôle des communications.
Le serveur DNS peut collecter de nombreuses informations sur les échanges, puisque vous vous adressez à lui en lui fournissant votre adresse et l'adresse de celui avec qui vous voulez communiquer. Il sait donc qui parle avec qui. Et l'on sait nous, aujourd'hui, la valeur que revêtent ces données, notamment pour les publicitaires.
Par ailleurs un serveur DNS peut tricher, mentir. Un serveur DNS menteur est un serveur DNS qui, lorsque vous lui communiquez un nom de domaine, vous répond autre chose que l'adresse IP associée. Pourquoi un serveur mentirait-il ? Parce qu'il préfère vous renvoyer sur une page de publicité lui appartenant plutôt que simplement vous dire qu'un nom de domaine demandé n'est associé à aucune adresse IP (ce que fait par défaut OpenDNS, c'est un de ses modes de rémunération). Parce qu'on lui a demandé d'interdire l'accès à certains domaines (illégaux, immoraux, indésirables...). Parce qu'il pense que vous aurez une réponse plus pertinente en consultant une page que son intelligence artificielle aura sélectionnée plutôt que celle que vous lui aviez demandée (ceci est une anticipation de l'auteur). Un serveur DNS peut également utiliser d'autres mécanismes de tricherie, comme faire preuve de mauvaise volonté, en répondant correctement, mais parfois plus lentement pour certains sites que pour d'autres.
Le contrôle des requêtes DNS est un enjeu majeur, tant que ce sont encore des humains qui utilisent le web.
Alors, imaginons que Google décide de configurer par défaut son navigateur Chrome (devenu le navigateur le plus utilisé en 2012, avec près de 50% du marché aujourd'hui) pour qu'il utilise ses serveurs DNS, ou son Chrome OS, voire le système Android. Aucun utilisateur ne s'en soucierait, mais il recentraliserait ainsi le contrôle d'un point névralgique d'internet.
La question de ce qu'un Google ferait de sa maîtrise du DNS dans les faits reste ouverte, mais la question de ce qu'il pourrait faire alors et qu'il ne peut pas faire sinon, elle est déjà tranchée. C'est en cela que le maintien de la décentralisation est fondamental, tout simplement pour ne pas faire des seigneurs là où ce n'est pas nécessaire.
Recentralisations du web
Internet a donc une assise historique et technique plutôt favorable à la décentralisation, même s'il existe des faiblesses et si sa neutralité originelle est aujourd'hui menacée.
En revanche le web, son application phare, a subi ces dix dernières années un mouvement très impressionnant de centralisation.
« Des services comme les réseaux sociaux, les outils de messagerie, les applications de stockage de contenus se fondent sur des modèles techniques et économiques dans lesquels les utilisateurs demandent des services à de puissants serveurs qui stockent de l'information et/ou gèrent le trafic. (Paloque-Berges and Masutti, 2013)[20] »
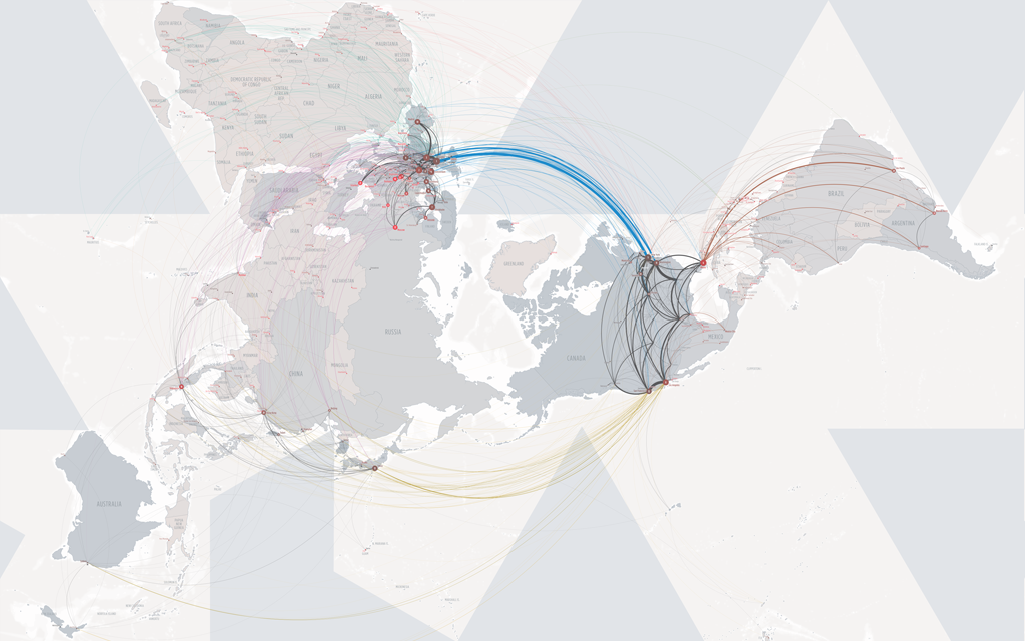
Carte du trafic sur Internet (2011 pour la liste des sites, 2015 pour le trafic)
 | En bleu, les États-Unis, en jaune la Chine, en vert l'Inde, en rouge la Russie, en violet le Japon. Au centre, Google et Facebook ; à proximité, Youtube, Yahoo, puis Twitter et Linkedin, Microsoft Live ; et en périphérie Wikipédia et Worpress. Carte interactive : http://internet-map.net/ |
Recentralisation du Web : Google, les réseaux sociaux... ou Wikipédia
À l'origine, le web est donc une application internet qui permet à chacun de mettre à disposition du contenu, puis des services, sur un serveur pour tout le monde. La question de le recherche dans cette masse de contenu a conduit le développement de plusieurs moteurs de recherche, dont Google a pris progressivement la tête, pour représenter plus de 90% des recherches aujourd'hui dans le monde.
L'accès à un site web, sa notoriété, dépend donc quasiment d'un unique acteur, qui peut décider ce qu'il met en avant, ou ce qu'il enfouit dans le web profond[22].
Facebook est devenu un portail d'accès à internet dont l'objectif même est de conserver ses utilisateurs en son sein, dans l'objectif de capter leur attention, collecter leurs données personnelles et leur vendre de la publicité.
Youtube est un passage obligé pour diffuser des vidéos, étrange retour à la chaîne de télévision unique.
Mais certains services associatif et libre, comme Wikipédia peuvent également participer à une forme de centralisation. Ainsi Wikipédia capte de nombreuses recherches sur internet, avec la connivence des moteurs de recherche qui placent souvent ses articles en première réponse ou en encart.
Adresses IP publiques et production d'information
Pour mettre à disposition de l'information, il faut pouvoir communiquer une adresse fiable où trouver cette information. Or la faible disponibilité des adresses IP fixes et publiques « ne permet pas aux utilisateurs de fournir du contenu et des applications en auto-hébergement (La Quadrature du Net, 2017)[23] »
.
Complément
Pour que chaque ordinateur puisse être à égalité dans sa capacité de communiquer avec les autres sur Internet, il faut qu'il dispose d'une adresse IP fixe et publique. Dans le cas contraire, un ordinateur sans adresse IP publique dépend d'un autre ordinateur qui est en charge de faire de la traduction d'adresse pour lui (NAT pour Network Address Translation). Ce dernier agit comme un intermédiaire entre l'ordinateur et internet, compliquant certains usages, notamment ceux qui visent à publier de l'information. (tandis que la consommation d'information reste elle aussi facile).
Or de nombreuses adresses, en particulier domestiques, sont aujourd'hui dans ce cas. La raison principale, technique, est liée au fait que les adresses IP ont été prévues initialement pour être codées sur 32 bits, ce qui ne permet que quatre milliards de possibilités, aujourd'hui dépassées.
Le protocole IPv6 propose des adresses sur 128 bits, ce qui permettra à chaque ordinateur de disposer d'une adresse propre, mais des difficultés techniques rendent son déploiement compliqué.
Asymétrie des connexions ADSL, structure d'internet, participation à la centralisation du web
L'ADSL a popularisé l'accès à internet des foyers, tout en introduisant une règle technique qui induit une certaine vision des échanges d'information, la connexion asymétrique. Une connexion ADSL fournit un fort débit entrant (un gros tuyau pour recevoir des données) et un faible débit sortant (un petit tuyau pour envoyer des données). C'est tout à fait adapté à un usage "orienté consommateur" d'internet, un peu sur le modèle de la télévision ou de la radio. L'utilisateur demande à consulter quelque chose (il envoie peu de données pour cela), il reçoit du contenu (il reçoit beaucoup de données).
Mais si vous voulez proposer vos propres contenus, avoir votre site web chez vous, mettre à disposition vos vidéos, alors, chaque fois que quelqu'un demandera à les consulter, ces contenus devront se contenter de votre faible débit sortant, vos contenus seront très lents à être délivrés. C'est pourquoi il devient inévitable de déposer ses contenus sur un serveur relié à internet par un autre moyen, Youtube par exemple, avec de gros tuyaux à sa disposition.
Si la connexion ADSL avait été symétrique, nos usages en auraient certainement été transformés (même si je ne prétends pas que ce soit la seule cause de la recentralisation du web, bien entendu, c'est une cause peut-être mésestimée).
La reconfiguration des terminaux
L'avènement des terminaux mobiles (smartphones et tablettes) est un sérieux coup de canif dans les capacités de décentralisations :
Ces terminaux sont ergonomiquement conçus pour la consultation et non pour la contribution, leurs utilisateurs tendent à lire plus qu'à écrire sur internet.
Les combats gagnés dans le domaine des PC sont réactivés (absence de solution libre, adhérence forte entre matériel et système d'exploitation, fermeture applicative et matérielle...).
«
« Le téléphone portable, c'est le rêve de Staline devenu réalité [...] Le processeur de communication des téléphones est complètement secret : nous ne savons même pas dans quel langage sont écrites ses instructions. (R. Stallman interviewé par Benoit, 2017)[24] »
Le non respect de la neutralité du Net[17] est particulièrement souligné sur les terminaux mobiles (DNS menteurs, systèmes fermés, enfermement applicatif...) (La Quadrature du Net, 2017)[23].
« Le terminal décide de plus en plus à notre place (https://www.franceinter.fr/societe/libre-de-surfer-sur-internet-avec-nos-smartphones-vraiment) »
.Le développement du Zero rating[25] permet aux fournisseurs de contenu importants d'asseoir leur position dominante.
« Devenu un poids lourd, Netflix estime qu'il n'a plus besoin de la neutralité du net (http://www.numerama.com/politique/263217-devenu-un-poids-lourd-netflix-estime-quil-na-plus-besoin-de-la-neutralite-du-net.html). »
Alternatives et résistances : Framachins, Framachines et Chatons
L'enjeu de la redécentralisation du web est la réappropriation par les citoyens du contrôle sur les applications d'Internet, face au pouvoir des GAFAM[7]. L'association française Framasoft a initié en 2014 un mouvement pour promouvoir des alternatives opérationnelles et initier un processus de dégafamisation. Si l'objectif affiché était opérationnel (redonner le choix aux utilisateurs et de limiter la concentration des données), cette action avait également comme fonction de poser une question : la dégafamisation est-elle possible, peut-on se passer des géants du Web ?
En 2018, on peut considérer que cette action a participé à apporter des réponses positives et à en explorer les voies.
Dégooglisons Internet (2014)
En 2014, Framasoft lance la campagne Dégooglisons Internet afin de proposer des services libres et ouverts, sans collecte de donnée personnelle, avec un financement par le don (Framasoft, 2014)[26].
33 services Framasoft en novembre 2018
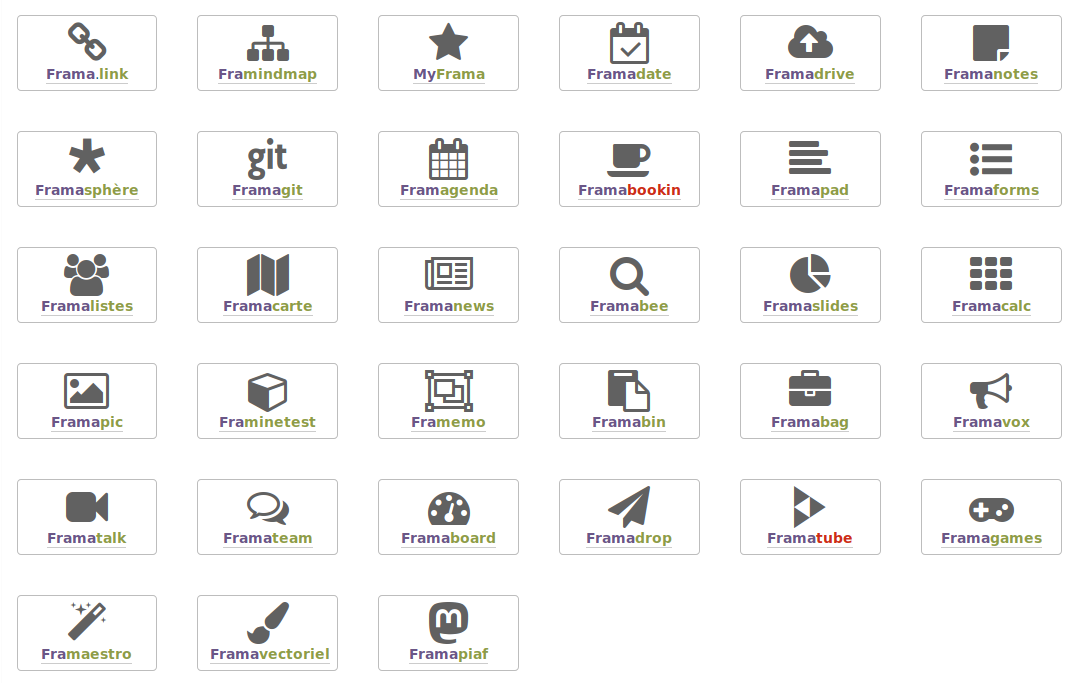
Écrire : Framapad
Calculer : Framacalc
Enquêter : Framaforms
Organiser : Framagenda
Organiser : Framadate
Organiser : Framaboard
Structurer : Framindmap
Dessiner : Framavectoriel
Exposer : Framaslides
Collaborer : Framaestro
Rechercher : Framabee
Réseauter : Framasphère
Réseauter : Framapiaf
Discuter : Framateam
Discuter : Framalistes
Discuter : Framatalk
Décider : Framavox
Cogiter : Framemo
Noter : Framanotes
Suivre l'actualité : Framabag
Suivre l'actualité : Framanews
Cartographier : Framacarte
Jouer : Framagames
Jouer : Framinetest
Partager : Framadrop
Partager : Framabin
Partager : Framapic
Partager : Framalink
Stocker : Framadrive
Stocker : MyFrama
Coder : Framagit
Lire : Framabookin
Diffuser : Framatube
Éléments en faveur de la possibilité de la dégafamisation
Les services ouverts par Framasoft comptent plusieurs milliers d'utilisateurs réguliers. Framadate est le plus utilisé avec plus de 1.000 sondages par jour (Hermann, 2016)[27]. Si la portée du succès reste limitée au regard de l'ensemble des usages, c'est à mettre également en regard des moyens mobilisés par l'association : 35 membres, 7 salariés, 250.000€ de budget annuel.
On observe également que des acteurs individuels ou institutionnels ont témoigné être parvenus à une dégafamisation partielle ou totale (par exemple Granier, 2016[28] ou Joffredo, 2017[29]). Framasoft n'est pas le seul vecteur de ce mouvement, mais il en est emblématique et son influence s'étend à l'international (par exemple Coca, 2018[30]).
Tentative (sauvage) de comparaison Framasoft/GAFAM
Le tableau ci-après esquisse un comparatif en ordre de grandeur, qui, même s'il est loin d'être rigoureux, permet d'observer qu'à moyens égaux Framasoft parviendrait à gérer à peu près la même quantité d'usages que les GAFAM. La décentralisation des moyens serait donc économiquement possible (un travail beaucoup plus rigoureux serait néanmoins utile pour estimer le budget consolidé consacré au Web des GAFAM, intégrer les paramètres telles que la capitalisation ou la trésorerie, évaluer le nombre d'utilisateurs, localiser à la France...).
Budget Framasoft € | Budget GAFAM € | Rapport |
250.000 | 250.000.000.000 | 1/1.000.000 |
Utilisateurs Framasoft | Utilisateurs GAFAM | |
5.000 | 5.000.000.000 | 1/1.000.000 |
Témoignage personnel
À titre personnel je n'utilise presque plus aucun des services des géants du web depuis environ deux ans. Au delà de mon engagement, il s'agit d'une expérience permettant de valider l'hypothèse d'indépendance. En 2018, je n'utilise plus que Twitter (indépendant), et marginalement, c'est à dire moins d'une fois par mois, LinkedIn (Microsoft), Youtube (Google) et Google Search.
S'il n'a pas valeur de généralité ce témoignage montre que la dégafamisation est donc possible.
Quelques pistes concrètes
On trouve aujourd'hui en ligne plusieurs manuels et conseils pour la dégafamisation. Mentionnons ceux de l'ouvrage Surveillance (Nitot, 2016)[31] qui ont l'avantage de chercher à s'adresser au public le plus large, et ajoutons les nôtres.
Ce que je peux faire demain
Changer de navigateur
Firefox et ses dérivés (par exemple Tor Brower) sont aujourd'hui les seuls navigateurs GAFAM-free; Firefox rend un service comparable à ses concurrents.
Changer de moteur de recherche
Il existe plusieurs alternatives à Google Search, je citerai : Duckduckgo et Qwant. Qwant ayant en outre l'avantage d'être français et de chercher à développer ses propres index de recherche, c'est aujourd'hui mon premier choix (il lui manque d'être un logiciel libre).
Ce que je peux faire cette semaine
Changer quelques habitudes simples
L'exploration du site de Framasoft permet de trouver par où commencer en fonction de ses usages ; on citera par exemple : Framadate pour la prise de rendez-vous, Framadrop pour le partage de fichier et OpenStreetMap pour étudier ses parcours à pied, en vélo ou en voiture.
Utiliser un logiciel de mail local
Thunderbird est un logiciel libre permettant de lire et écrire ses mails sur son ordinateur, à la différence des webmails qui sont des applications en ligne. Le premier intérêt de disposer d'un client mail local est qu'il permet de disposer de plusieurs adresses et de ne pas dépendre en terme d'interface d'un seul fournisseur de mail. Ce qui est la première étape pour envisager d'en changer.
Changer de moyens de communication audio/vidéo
Le logiciel Jitsi permet d'initier des vidéo-conférences sans créer de compte. Il existe de nombreux hébergeur, on citera meet.jit.si (l'éditeur du logiciel) et framatalk.org (chez Framasoft).

Ce que je peux faire ce mois-ci
Faire évoluer mes pratiques bureautiques
Il n'existe pas d'alternatives totalement satisfaisantes aux suites bureautiques en ligne, mais il est des contextes où des outils plus simples comme Etherpad peuvent suffire (hébergé par Framasoft ou Chapril par exemple) et il y a des outils comme Framavectoriel ou Framindmap à découvrir.
Changer de canaux de discussion
Des logiciels de discussion comme Mattermost (Framateam) ou les réseaux sociaux Mastodon et Diaspora* offrent des alternatives en terme de discussion (chat).
Acheter un nom de domaine
Un nom de domaine coûte environ 10€ par an et peut servir à plusieurs amis ou membres de la famille. L'avantage est qu'il permet de créer une adresse mail indépendante de son fournisseur de service ; c'est la seconde étape pour se rendre autonome vis à vis de ce dernier.
Étudier les modèles économiques et les conditions d'utilisation de mes services
Les services que nous utilisons sont associés à des conditions générales d'utilisation (CGU ou TOS pour Terms Of Service en anglais) et les informations concernant leurs modèles économiques sont en général disponibles sur Wikipédia. Leur lecture permet de comprendre ce à quoi nous consentons en échange du service utilisé.

Ce que je peux faire cette année
Intégrer des réseaux sociaux décentralisés
Diaspora* et Mastodon sont deux réseaux sociaux offrant des alternatives respectivement à Facebook et Twitter. Le changement de réseau social est difficile car lorsqu'on change d'outil on n'emporte pas son réseau avec soi. Mais il est tout à fait possible de commencer à créer un réseau parallèle sans renoncer aux réseaux auxquels on est déjà bien intégrés.
Changer de système d'exploitation
Le système Linux est devenu accessible à tous, des distributions comme Ubuntu et ses variantes rendent par ailleurs l'installation simple. Il existe des associations qui aident au démarrage et peuvent répondre aux questions que se posent les nouveaux utilisateurs.
Libérer mon téléphone
Il existe un des systèmes d'exploitation basés sur Android qui diminuent l'empreinte de Google, et les systèmes Linux pour téléphones sont en train de se consolider.
Me faire héberger
L’auto-hébergement consiste à disposer de serveurs à domicile (avec un Raspberry Pi par exemple) ou chez un hébergeur (Gandi...). Des intégrations spécifiques (Yunohost, Cosy Cloud) rendent aujourd'hui cette option plus accessible. Il reste néanmoins des points délicats (sécurité des accès, sauvegarde des données...) qui demandent un investissement important. Des associations se constituent pour permettre à des collectifs de partager les efforts nécessaires à l'auto-hébergement.
Reprendre et rendre le pouvoir (à des Chatons...)
Début 2016, Framasoft lance une nouvelle campagne et appelle à la création du CHATONS, le Collectif d'Hébergeurs Alternatifs, Transparents, Ouverts, Neutres et Solidaires (Framasoft, 2016)[32].
Cette initiative vise à démultiplier l'expérience Dégooglisons Internet tout en évitant que Framasoft ne devienne à son tour un foyer de centralisation. Le collectif compte en 2018 une soixantaine de membres, avec des profils très divers (en terme de services offerts, de formes juridiques...).
Fin 2016 s'est créée à l'UTC l'association Picasoft, devenue Chaton en 2017.
