Écrire avec une machine à calculer, écrire pour une machine à calculer
Un ordinateur est fondamentalement une machine à calculer, c'est à dire à manipuler des nombres par des opérations arithmétiques. Comme l'avait anticipé Vannevar Bush dans As we may think la mécanisation du traitement des nombres porte en elle une forme d'universalité, car le calcul réalisé par la machine peut être mobilisé pour travailler sur n'importe quel codage numérique d'information : « [The advanced arithmetical machines of the future] will be far more versatile than present commercial machines, so that they may readily be adapted for a wide variety of operations (Bush, 1945[1]) »
. Ainsi les signes qui fondent la communication entre humains - textes, paroles, images - sont codables, donc calculables. Les ordinateurs peuvent manipuler des signes, et ainsi devenir des outils sémiotiques, des machines à lire et à écrire.
Or même mobilisés ainsi les ordinateurs restent fondamentalement des machines à calculer. De cette dualité entre signe et calcul naît une problématique qui s'exprime aussi bien dans le champ documentaire que dans le champ des bases de données, et que l'on peut résumer par une double question : qu'est ce qui est document ? qu'est ce qui est donnée ? Une première réponse permet de structurer les champs de l'ingénierie documentaire et de l'ingénierie des bases de données : le document est ce qui est accessible et interprétable par l'homme et la donnée est ce qui est accessible et calculable par la machine.
Écrire avec une machine à calculer : le point de vue du document
L'informatique orientée document est largement popularisée par le biais de la bureautique. Dans ce contexte la frontière entre document et donnée est assez marquée. En revanche, il existe un autre axe, que nous avons appelé les chaînes éditoriales (Crozat, 2007[2], 2012[3]). Selon cette approche, le document est représenté par un ensemble de fichiers XML, qui codent à la fois les signes (lettres, images...) et des métadonnées décrivant ces signes. Cet ensemble de fichiers constituent une forme génératrice, qui est transformée par la machine en formes de publication lisibles par les humains (un fichier PDF ou un site HTML par exemple). Cette approche permet notamment le polymorphisme : une forme génératrice permet d'obtenir plusieurs formes de publication adaptées à plusieurs contextes de lecture, en appliquant différents algorithmes de transformations.
L'humain qui écrit et gère des formes génératrices XML avec une chaîne éditoriale est donc également en situation de production explicite de données et de commande de traitements. Un des enjeux des chaînes éditoriales est de fait de donner à voir et à contrôler les calculs.
Calculer avec une machine à écrire : le point de vue de la donnée
L'informatique orientée données est a priori ancrée dans le calcul. Une base de données relationnelle manipule des tableaux pour les croiser, les projeter, les agréger... Mais les résultats de ces calculs sont - souvent - destinés à des êtres humains. Les données calculées doivent alors être documentarisées, c'est à dire représentées sous la forme de signes humainement interprétables. Le document est alors le résultat d'un nouveau calcul. On trouve également le mouvement inverse, à savoir une donnéisation (on pourra préférer à ce néologisme peu élégant la "mise en données" proposée par Le grand dictionnaire terminologique ou l'anglicisme datafication). Il s'agit ici de rendre calculable des productions originellement sémiotiques. C'est la donnée qui est ici le produit du calcul.
En fait toute interaction homme-machine procède d'une documentarisation et d'une donnéeisation, puisque l'ordinateur fabrique des signes avec des données pour se faire comprendre de l'homme et que l'homme en retour fabrique des données avec des signes pour se faire comprendre de la machine.
Données et des documents : de l'intégration technique à l'intégration conceptuelle
Historiquement la séparation du champ des données et des documents peut se dater assez précisément : par un tournant théorique au début des années 1970 (modèle relationnel de Codd en 1970 et langage de balisage GML par Goldfarb en 1969) ; puis un tournant technique au début des années 1980 avec les premiers systèmes de gestion de bases de données relationnelles d'un côté et les premières chaînes éditoriales SGML et LaTeX de l'autre. Cette séparation reste assez nette jusqu'à l'apparition du Web dit dynamique, c'est à dire de la génération automatique de pages HTML (des documents) en fonction de paramètres (des données). Les Web CMS, gestionnaires de contenus au format HTML, commencent à stocker des documents au moyens de bases de données.
La frontière se fissure également lorsque le format XML, dont les fichiers se nomment des documents, est massivement utilisé pour faire de l'échange de données entre systèmes. Ou quand au sein du mouvement NoSQL se développent des bases de données qui stockent des objets appelés documents dans un format comme JSON qui est à l'origine un format adossé à un langage de programmation. On assiste à une perméabilité technologique, les mêmes techniques sont utilisées pour manipuler des données et des documents ; et une perméabilité terminologique, les mêmes mots désignent des objets que l'on ne sait plus du tout classer côté donnée ou côté document.
Il y a fusion des formats, fusion des domaines, et finalement fusion des gestes d'écrire et de calculer.
Écrire pour les machines : extension du domaine de l'ingénierie documentaire
L'ingénierie des documents numérique consiste à étudier les liens entre systèmes, calculs et signes. Les chaînes éditoriales XML intègrent la dimension calculatoire aux processus d'écriture, lorsqu'elles conduisent un auteur à expliciter des structures, à gérer des références ou à programmer des interactions. Son objectif originel est d'optimiser la production et la gestion des documents pour l'interprétation humaine.
Mais la question se pose à présent de la production d'information non plus seulement pour les humains, mais aussi pour les machines. Le Web de données repose sur l'idée de fournir aux machines des ressources consultables sur Internet à l'instar du Web documentaire pour les humains. Un ordinateur peut ainsi accéder à Wikipédia pour connaître la date de naissance de Jacques Brel, exactement comme le ferait un être humain.
La question adressée par l'ingénierie documentaire ne peut plus se limiter à se demander comment écrire avec ces machines à calculer que sont les ordinateurs, elle doit intégrer le fait même d'écrire pour les machines, c'est à dire de comment produire quelles données pour obtenir quels effets, répondre à quelles fonctions.
Concrètement les fonctions des chaînes éditoriales sont revisitées par ce nouvel objectif. Par exemple, le polymorphisme ne concerne plus seulement la génération de plusieurs formes pour l'interprétation humaine, mais également de formes destinées au calcul, l'enjeu étant in fine que l'information soit produite et distribuée pour les hommes et pour les machines.
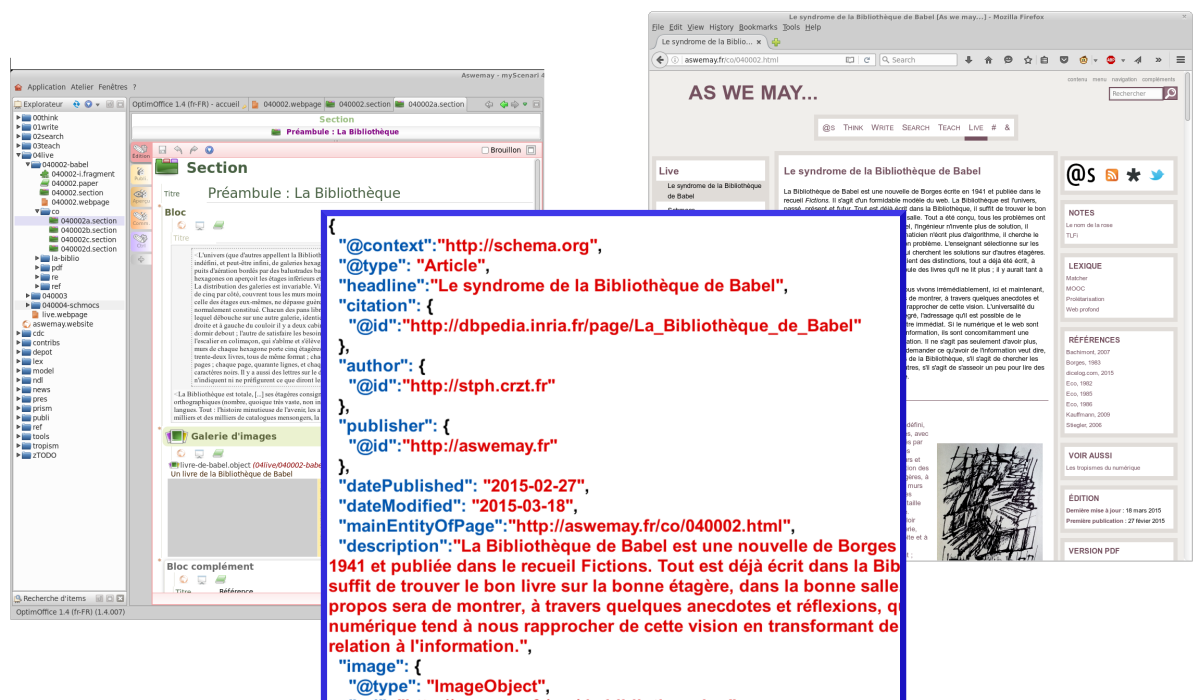
Les chaînes éditoriales XML réinterrogent les pratiques d'écriture numérique, en posant des questions nouvelles à l'auteur, celui qui écrit dans l'espace du calcul. En instrumentant une écriture qui produit des documents et des données, elles poursuivent et complexifient encore ce mouvement. Cela permet de prolonger l'exploration des fonctions et tropismes du numérique, pour les étudier, en anticiper les conséquences. Cela permet aussi de prolonger le développement d'un programme de formation à la littératie numérique, qui s'attache à équiper les hommes des moyens de comprendre et contrôler leurs pratiques d'écriture avec un ordinateur.