L'écriture numérique est une programmation informatique
La dualité écriture-programmation de l'écriture numérique
Toute écriture numérique procède techniquement d'une programmation ; le résultat de l'acte d'écriture avec un ordinateur est un code informatique dont l'exécution produit des signes sur un terminal de lecture qui donnent lieu à des interprétations.
L'écriture numérique et la programmation informatique semblent relever de deux pratiques différentes : l'écriture numérique consisterait à coder des données, les signes que l'on code et que l'on souhaite voir restitués "tels quels" ; tandis que la programmation consisterait à coder les calculs qui manipulent ces signes, ce qui serait de l'ordre du traitement.
Or cette séparation est fragile, d'abord au niveau logique de l'informatique où la frontière entre données et traitements est poreuse ; mais également au niveau sémiotique de l'écriture où la frontière entre écriture de contenus et écriture de programmes est également difficile à établir systématiquement dans le contexte du numérique.
Ce qu'il reste de la séparation entre écriture et programmation se cristallise dans le degré de conscience et d'intentionnalité de programmer que l'acte d'écrire inclut. Écrire relève d'une programmation, mais celle-ci peut être plus ou moins prégnante sur celle là ; et la maîtrise de l'articulation entre le niveau logique de la programmation et le niveau sémiotique de l'écriture est un enjeu majeur de l'écriture numérique.
Rappel : Écriture numérique et codage de signes
L'écriture consiste en l'inscription intentionnelle de signes en vue d'une transmission et d'une interprétation par un être humain. L'écriture numérique se caractérise par le fait que les inscriptions sont codées via un dispositif d'écriture numérique et décodées via un dispositif de lecture numérique.

Les programmes sont des données, les données sont des programmes
Fragilité théorique de la séparation entre données et instructions
La rupture fondamentale apportée par l'ordinateur, qui le distingue des automates qui le précédent est l'indifférenciation du programme et de la donnée, ou dit autrement, le fait de considérer un programme comme une donnée.
« The computer is based on a fixed hardware platform, capable of executing a fixed repertoire of instructions. At the same time, these instructions can be used and combined like building blocks, yielding abitrarily sophisticated programs. Moreover, the logic of the program is not embeded in the hardware, as it was in mechanical computers predating 1930. Instead, the program's code is stored and manipulated in the computer memory, just like data, becoming what is known as "software". (Nisan and Schocken, 2005) [fr][1] »
Séparation entre données et traitements au niveau du langage machine
Si on étudie le fonctionnement bas niveau d'un ordinateur on peut considérer d'un certain point de vue qu'il y a d'un côté le programme qui calcule, et de l'autre les données qui sont calculées ; d'un côté le microprocesseur, de l'autre la mémoire. Il y a bien dans la machine des séquences binaires qui donnent des ordres (les instructions) et d'autres qui paramètrent ces ordres (les données). Ces séquences peuvent être séparées au sein de mémoires différentes dans la machine, pour des raisons pratiques, mais ce n'est pas nécessaire.
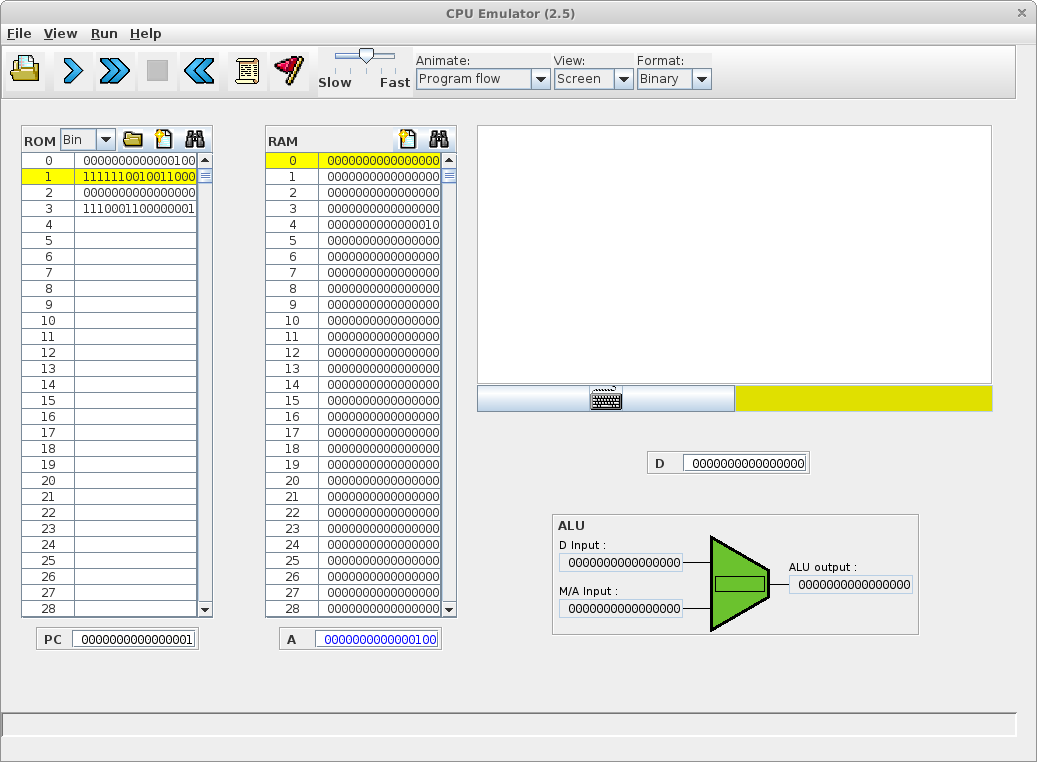
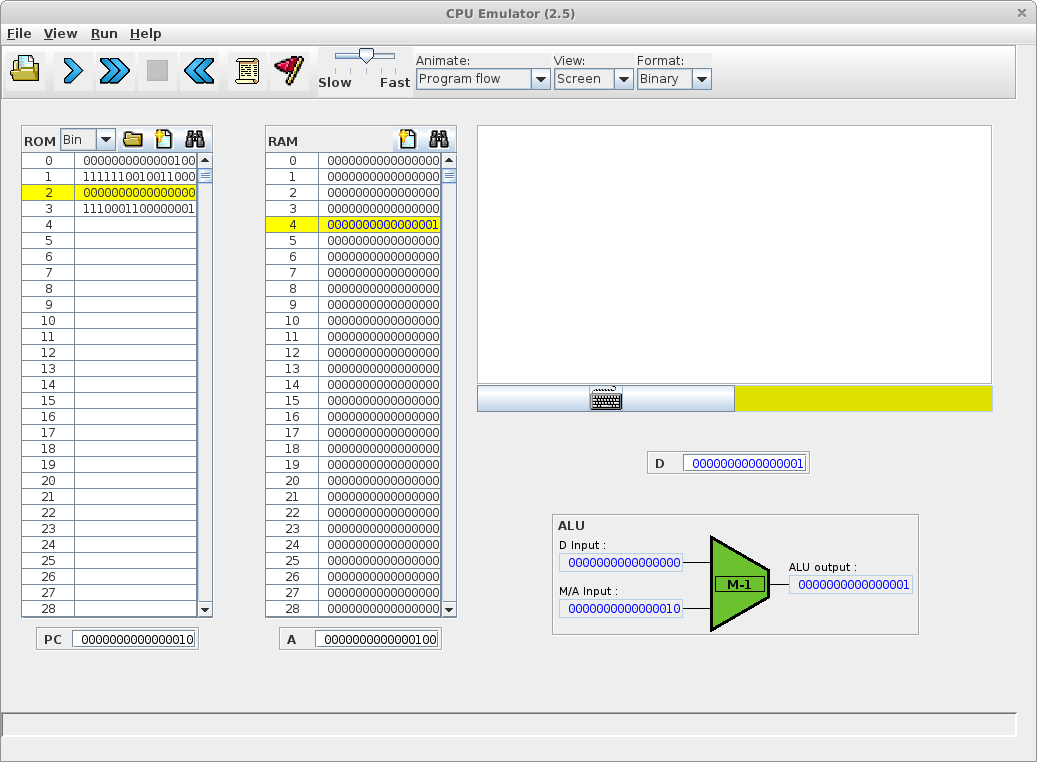
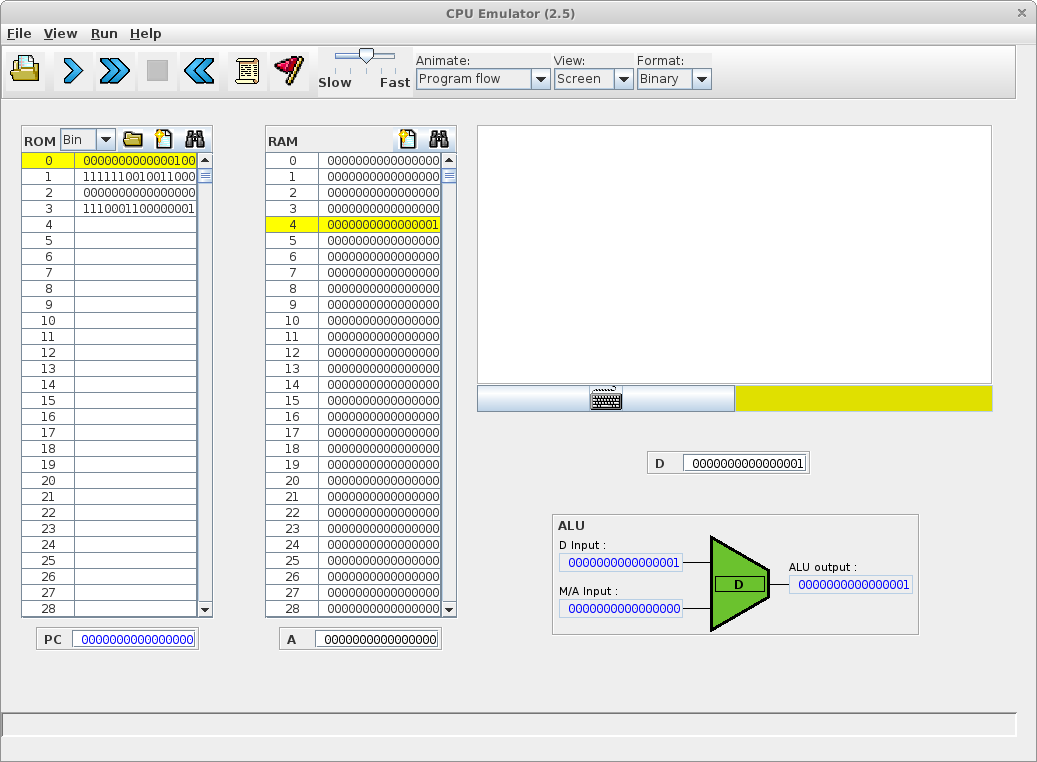
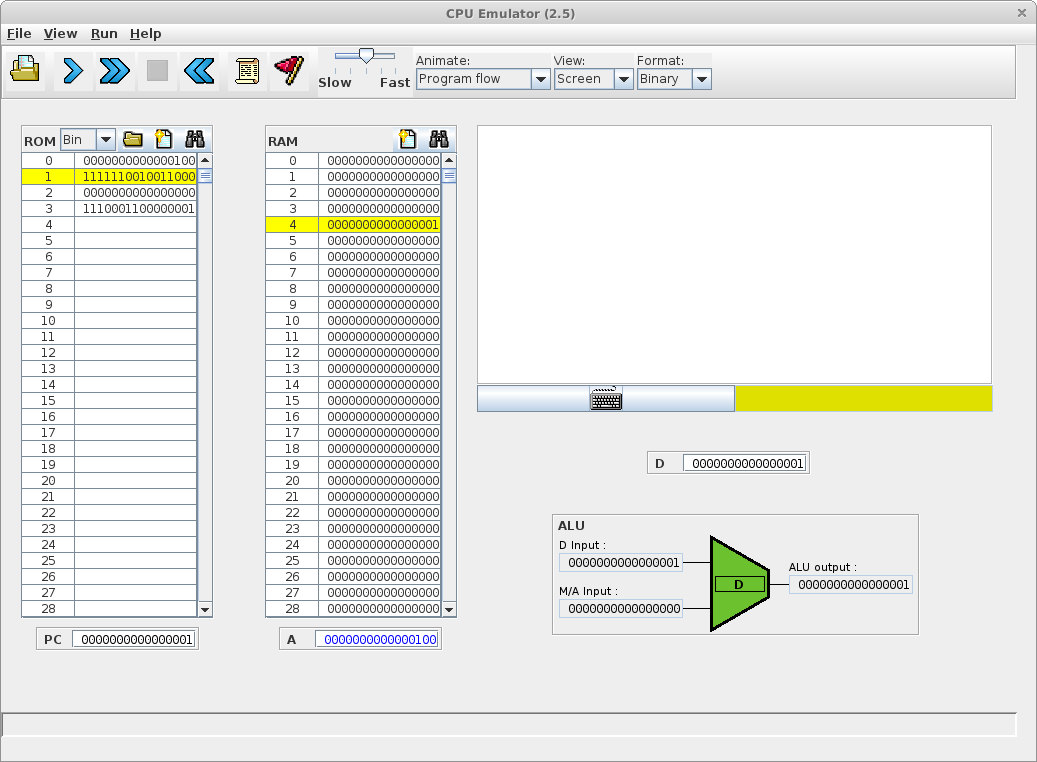
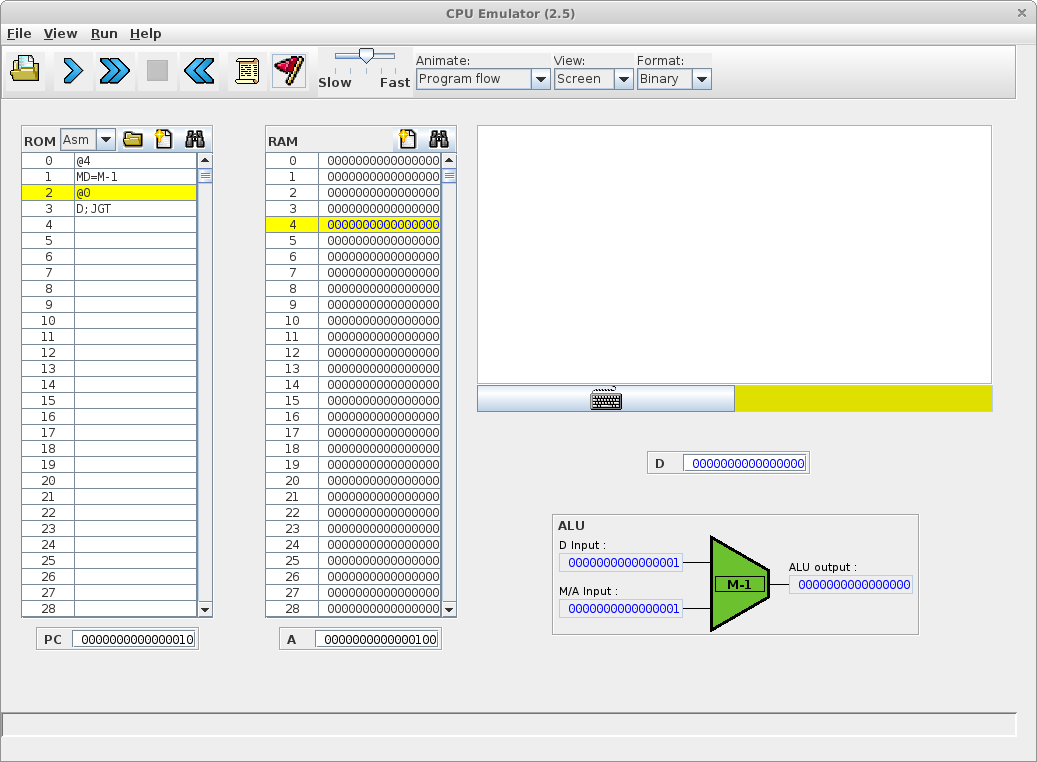
Simulation d'une exécution de langage machine avec deux séquences binaires
Cette simulation a été réalisée avec CPU Emulator, Version 2.5 (http://www.nand2tetris.org). Elle se base sur un ordinateur avec deux mémoires séparées, une pour le programme (ROM) et une pour les données (RAM).


La machine de Turing universelle
L'exemple précédent illustre une machine de Turing, avec d'un côté un programme et de l'autre les données impactées par le programme. Mais on peut également le représenter sous la forme d'une machine de Turing universelle, avec une seule mémoire comportant le programme et les données. Il n'y a plus qu'une seule séquence numérique dont la lecture et l'écriture entraîne des modifications des états mémoires, et par conséquent des périphériques de sortie, comme l'écran. Données et programmes sont alors confondus.
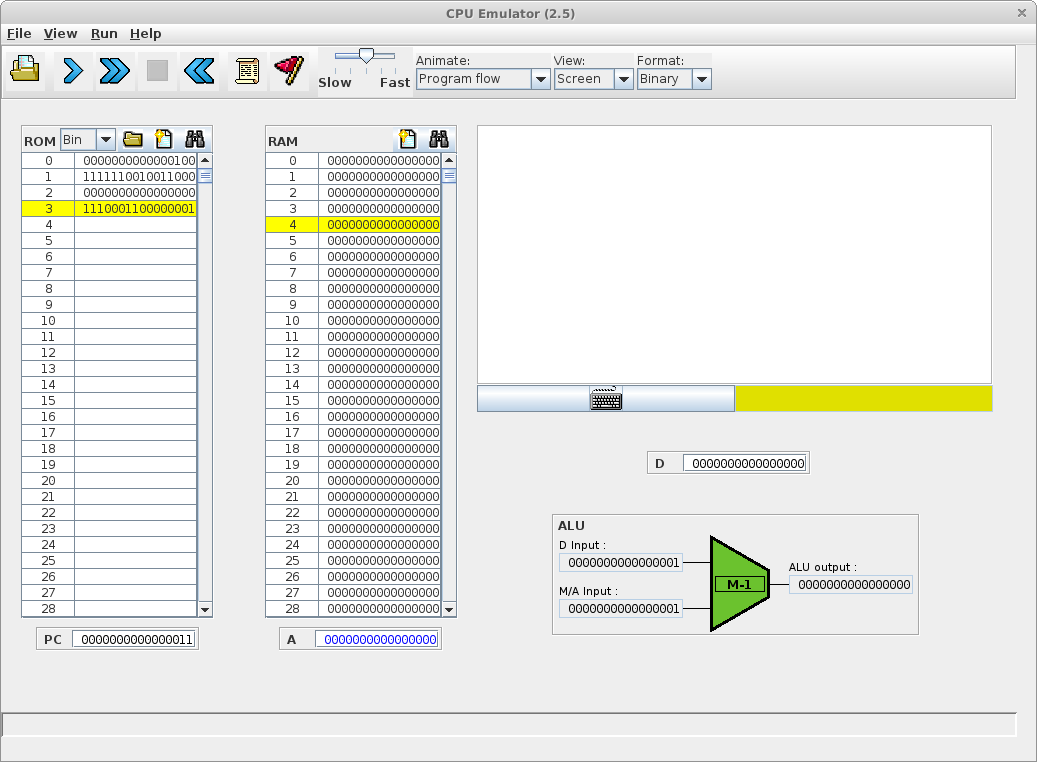
Simulation d'une exécution de langage machine avec une seule séquence binaire
Soit une machine composée d'un microprocesseur et d'une mémoire de 60 bits (5 fois 16 bits) et doté du langage machine Hack (Nisan and Schocken, 2005).
Soit la séquence binaire de 60 bits codant quatre instructions sur 16 bits en langage machine et stockant le résultat sur les 16 derniers bits :
0000 0000 0000 0100 1111 1100 1001 1000 0000 0000 0000 0000 1110 0011 0000 0001 0000 0000 0000 0010
Adresse | Langage machine | Assembleur | Signification |
|---|---|---|---|
0 | 0000 0000 0000 0100 | @4 | Charge la valeur 4 (0100) dans le registre A |
1 | 1111 1100 1001 1000 | MD=M-1 | Retire 1 à la valeur stockée à l'adresse mémoire stockée dans le registre A (donc à l'adresse 4) et stocke le résultat à la même adresse ainsi que dans le registre D |
2 | 0000 0000 0000 0000 | @0 | Charge la valeur 0 dans le registre A |
3 | 1110 0011 0000 0001 | D;JGT | Si ce qui est stocké dans le registre D est supérieur à 0 alors se repositionne sur l'instruction située à l'adresse mémoire stockée dans le registre A (ici retourne à la première instruction située à l'adresse 0), sinon avance à l'instruction suivante |
4 | 0000 0000 0000 0010 | @2 | Charge la valeur 2 (0010) dans le registre A |
Bien que le décodage montre des parties qui codent des instructions et d'autres des données, l'exécution de la séquence montre l'indifférenciation binaire entre programme et donnée.
L'exécution va ici modifier l'état des 2 derniers bits de la mémoire (la valeur sera décrémentée deux fois pour finir à zéro) :
0000 0000 0000 0100 1111 1100 1001 1000 0000 0000 0000 0000 1110 0011 0000 0001 0000 0000 0000 0000
Données et traitements du point de vue informatique
Fragilité technique de la séparation entre données et traitements
En conception informatique, on a tendance à privilégier la séparation entre données et programmes, notamment afin de pouvoir réutiliser les mêmes programmes pour des données différentes, ou inversement d'exploiter les mêmes données avec des traitements différents pour différents besoins fonctionnels.
Les méthodes de conception repose historiquement sur ce principe, comme la méthode MERISE qui sépare la conception entre le modèle des données et le modèle des traitements. En programmation orientée objet, les classes permettent de séparer les attributs (données) des méthodes (traitements). On retrouve également cette tendance au sein des architectures n-tier qui séparent les données stockées sur des serveurs de bases de données et les traitements implémentés au sein de serveurs applicatifs.
Néanmoins, au sein de certains paradigmes de programmation, cette posture n'est pas toujours aussi évidente. Par exemple en Lisp (programmation fonctionnelle) tout est fonction, donc les fonctions savent manipuler des fonctions, permettant la modification dynamique des programmes. De même en JavaScript (programmation orientée prototype), données et fonctions sont des objets dynamiques (variables). Ainsi les données peuvent être traitées comme des instructions et les instructions comme des données.
Par ailleurs, il existe des programme qui sont leurs propres données d'entrée, qui s'exécutent toujours de la même façon (les programmes d'amorçage) ; ou des programmes dont le résultat (la donnée de sortie) est un autre programme (c'est ce que fait un compilateur).
Exemple : Entité-Association (MERISE)
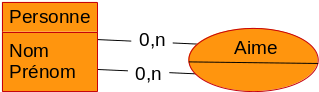
Un modèle conceptuel de données dans le formalisme MERISE ne représente que les données, les traitements sont représentés dans un autre modèle.
Exemple : Diagramme de classes (UML)
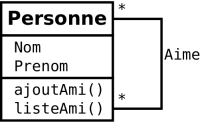
Un modèle conceptuel de données dans le formalisme objet d'UML représente les données (attributs) ainsi que les traitements principaux (méthodes).
Exemple : Classes Java
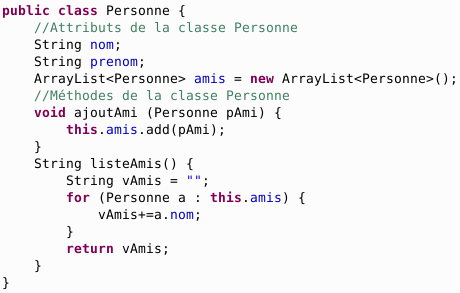
Un langage orienté objet comme Java procède de la programmation de classes qui contiennent des attributs (données) et des méthodes associées (traitements).
Exemple : Architecture 3-tier
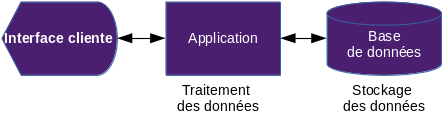
Une architecture 3-tier sépare le stockage des données et le traitement des données au sein de deux serveurs distincts.
Exemple : Données et fonctions en JavaScript
// La fonction dialogue est déclarée comme une donnée var debut = "hello"; var fin = "world"; var dialogue = function() {return debut + ' ' + fin;}; alert(dialogue()); | 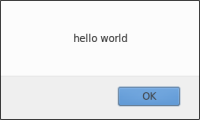 |
//La donnée message est utilisée comme une instruction de concaténation var debut = "hello"; var fin = "world"; var message = "debut + ' ' + fin"; var dialogue = function() {return eval(message);}; alert(dialogue()); | |
//La fonction dialogue peut être manipulée comme une donnée var debut = "hello"; var fin = "world"; var message = "debut + ' ' + fin"; var dialogue = function() {return eval(message);}; dialogue = dialogue.toString().toUpperCase(); alert(dialogue); | 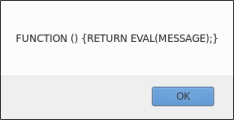 |
// La donnée message peut être manipulée pour modifier l'instruction qu'il représente var debut = "hello"; var fin = "world"; var message = "debut + ' ' + fin"; var dialogue = function() {return eval(message);}; message = message + ".toUpperCase()"; alert(dialogue()); | 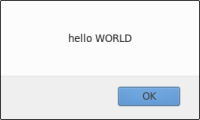 |
Complément
Exécuter le programme JavaScript : var-function-js.eWeb[2]
Écrire avec la conscience de programmer
Programmation explicite et programmation implicite
La programmation informatique a pour finalité la production de calculs. Mais tous les programmes informatiques qui interagissent avec des êtres humains le font par l'intermédiaire de signes qu'ils produisent et qui permettent l'interprétation du message par l'humain. Un tel acte de programmation remplit donc la même fonction qu'un acte d'écriture.
L'écriture numérique a de son côté pour finalité la production de signes. Mais elle ne peut le faire que par l'intermédiaire des calculs opérés par la machine. Elle peut procéder pour cela d'un codage logique d'instructions informatiques, c'est à dire d'une programmation explicite, ; ou bien de manipulations de si haut niveau qu'elles masquent le caractère programmatique de l'acte (on parlera d'une programmation implicite).
L'écriture numérique telle qu'elle est proposée via les dispositifs de type traitement de texte relève essentiellement d'une programmation implicite. Mais la programmation d'une macro au sein d'un tel logiciel devient un acte de programmation explicite.
Exemple : production de signes par programmation explicite et par programmation implicite
Éditeur WYSIWYM | 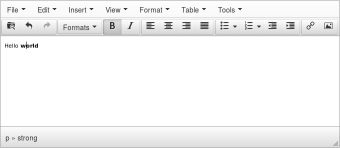 | |
Écriture HTML | <html> <body> <p>Hello <strong>world</strong></p> </body> </html> | |
Écriture JavaScript | <html> <body><p/></body> <script type="text/javascript"> var p = document.getElementsByTagName("p")[0] var s = document.createElement("strong"); var h = document.createTextNode("Hello "); var w = document.createTextNode("world"); p.appendChild(h); p.appendChild(s); s.appendChild(w); </script> </html> |
Programmation de bas niveau et programmation haut niveau
Tout acte de programmation par un être humain se fait par l'intermédiaire de signes qu'il manipule et qui produisent les séquences binaires en machine. La manipulation de ces signes peut se faire avec des langages de plus ou moins bas niveau, c'est à dire plus ou moins proche du langage élémentaire de la machine. Les langages de plus bas niveau sont les assembleurs qui correspondent quasiment aux instructions binaires, puis les langages procéduraux (Basic, Fortran, C, Pascal) qui restent logiquement proche du fonctionnement de l'ordinateur. Il existe ensuite des langages de plus haut niveau, qui s'éloignent de la machine, pour correspondre à des modes d'expression plus abstraits : les langages fonctionnels (Lisp), logique (Prolog), mathématiques (Matlab), orientés objets (Java), orientés données (SQL)... Il existe également des modes de programmation graphique, c'est à dire que le code est produit par la manipulation d'une interface graphique via la souris, par exemple le langage orienté données QBE, les logiciels de création multimédia (Director), les environnements graphiques de développement d'interfaces (WindowBuilder d'Eclipse), les logiciels d'ETL (Pentaho Data Integration)...
Écrire avec l'intention de programmer
Fragilité sémiotique de la séparation entre contenus statiques et comportements dynamiques
Du point de vue de l'auteur qui écrit, on peut considérer en première approximation qu'il y a deux catégories d'actes d'écriture numérique : les actes dont la fonction est de coder des signes (je viens d'encoder "je viens d'encoder") et ceux dont la fonction est de coder un programme qui va générer des signes et de l'interaction (par exemple associer un lien hypertexte à un mot). Cette différence se manifeste grosso modo d'un point de vue fonctionnel : d'un côté j'entre les signes qui seront restitués, le calcul mobilisé est implicite, il procède essentiellement du stockage et de la restitution ; de l'autre j'ajoute à ces signes des instructions qui vont commander du calcul, car je programme explicitement un comportement.
La question porte donc un curseur sémiotique-logique, mais il n'y a pas de frontière - la plupart des écritures numériques renvoient à des modes de codages sémiotique et logique et à des codes à vocation sémiotique et logique. Et le développement du numérique (ses tropismes), tend à rendre la zone de flou de plus en plus large. Dès qu'on n'écrit plus strictement pour l'impression, mais pour l'écran, on programme des interactions, même mineures, comme l'apparition d'une barre de défilement qui dépend de la longueur d'un texte, ou le plan interactif d'un document PDF dont on aura préalablement marqué les niveaux de titre.
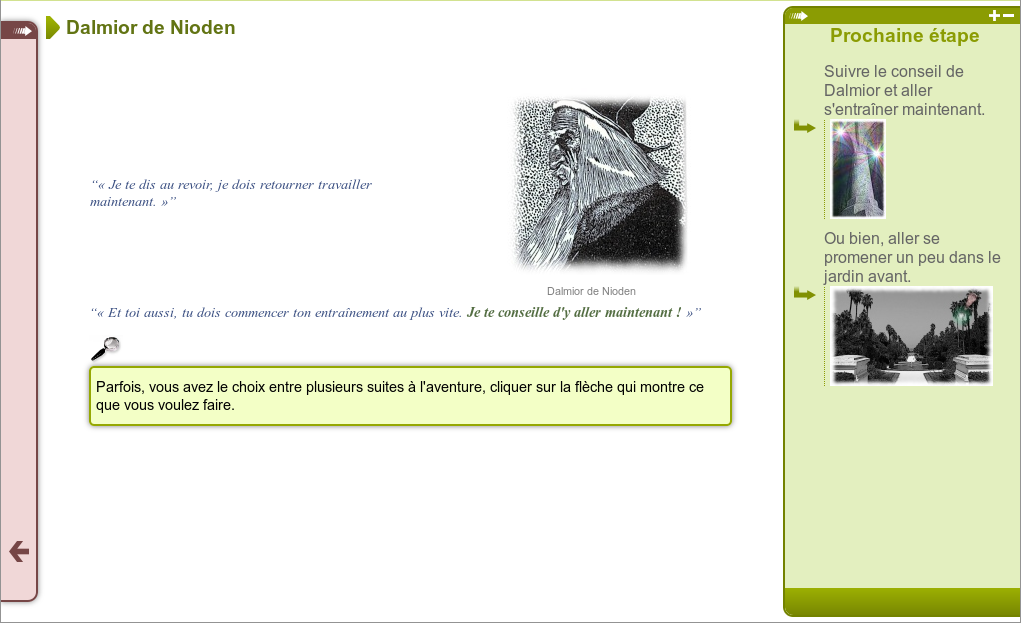
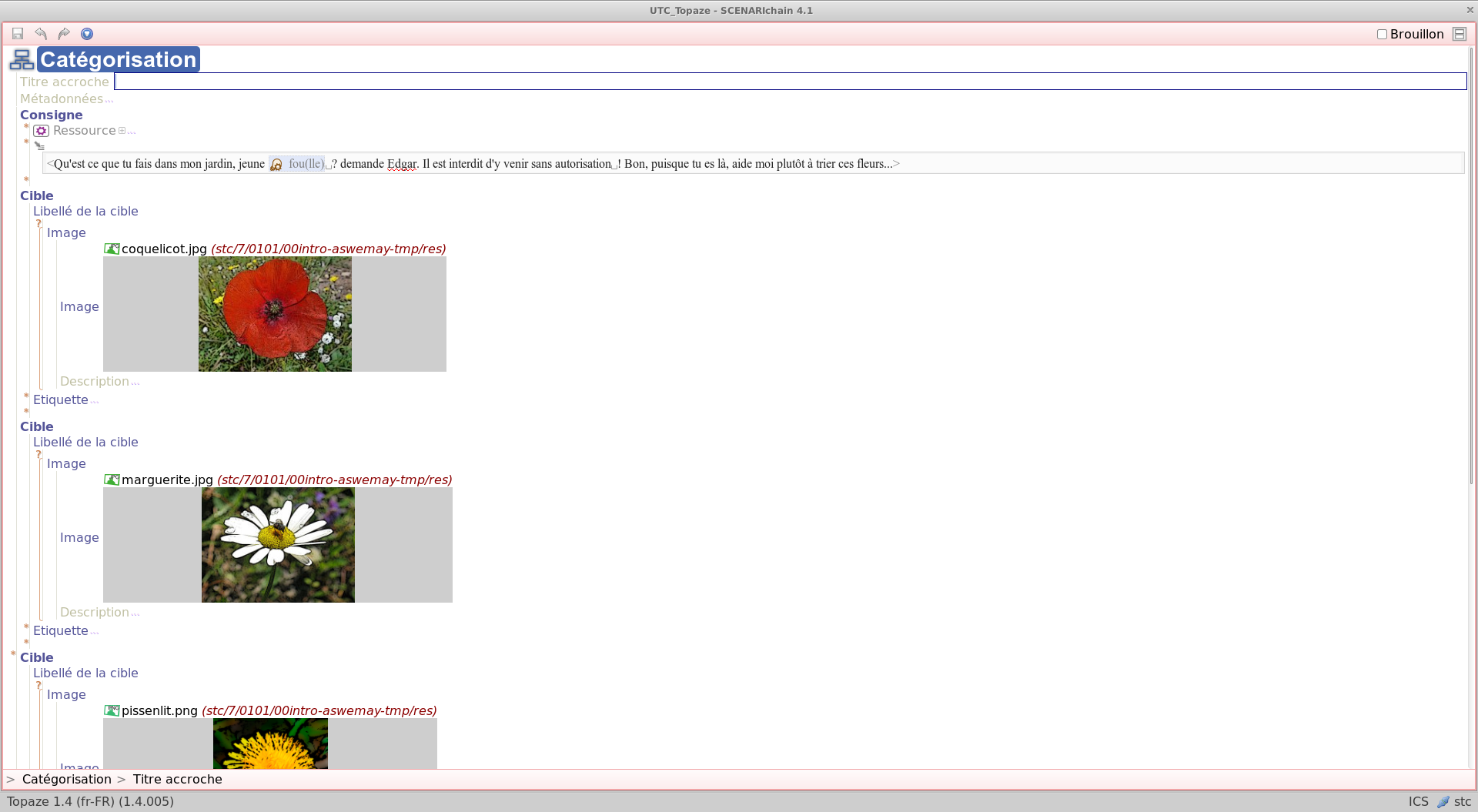
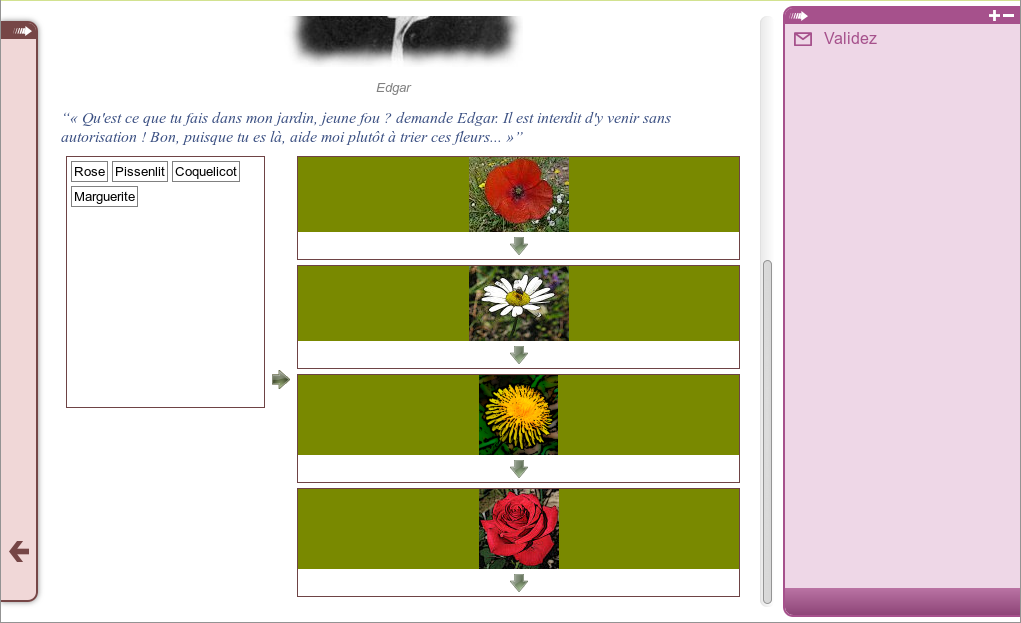
Exemple : contenus statiques et de comportements dynamiques
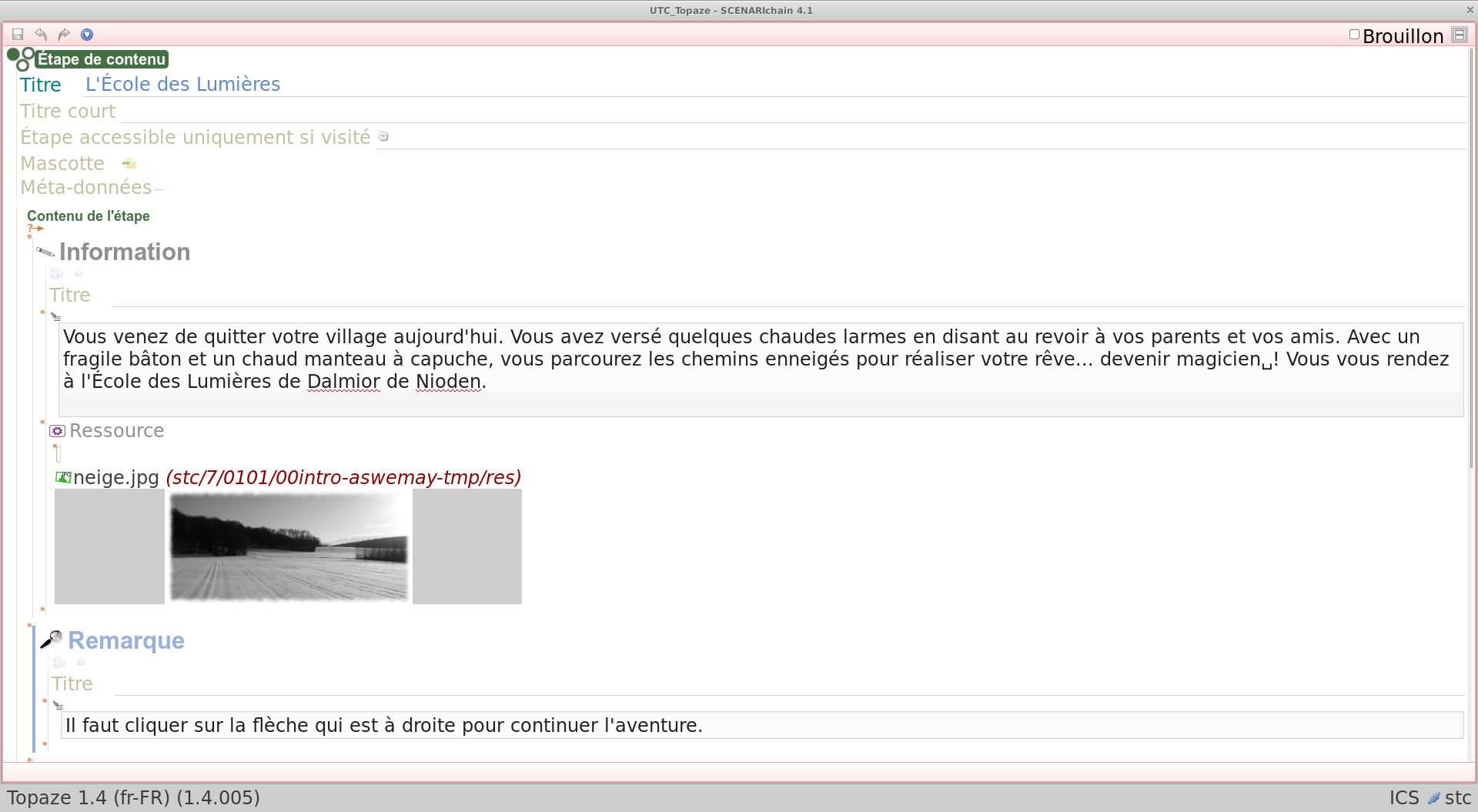
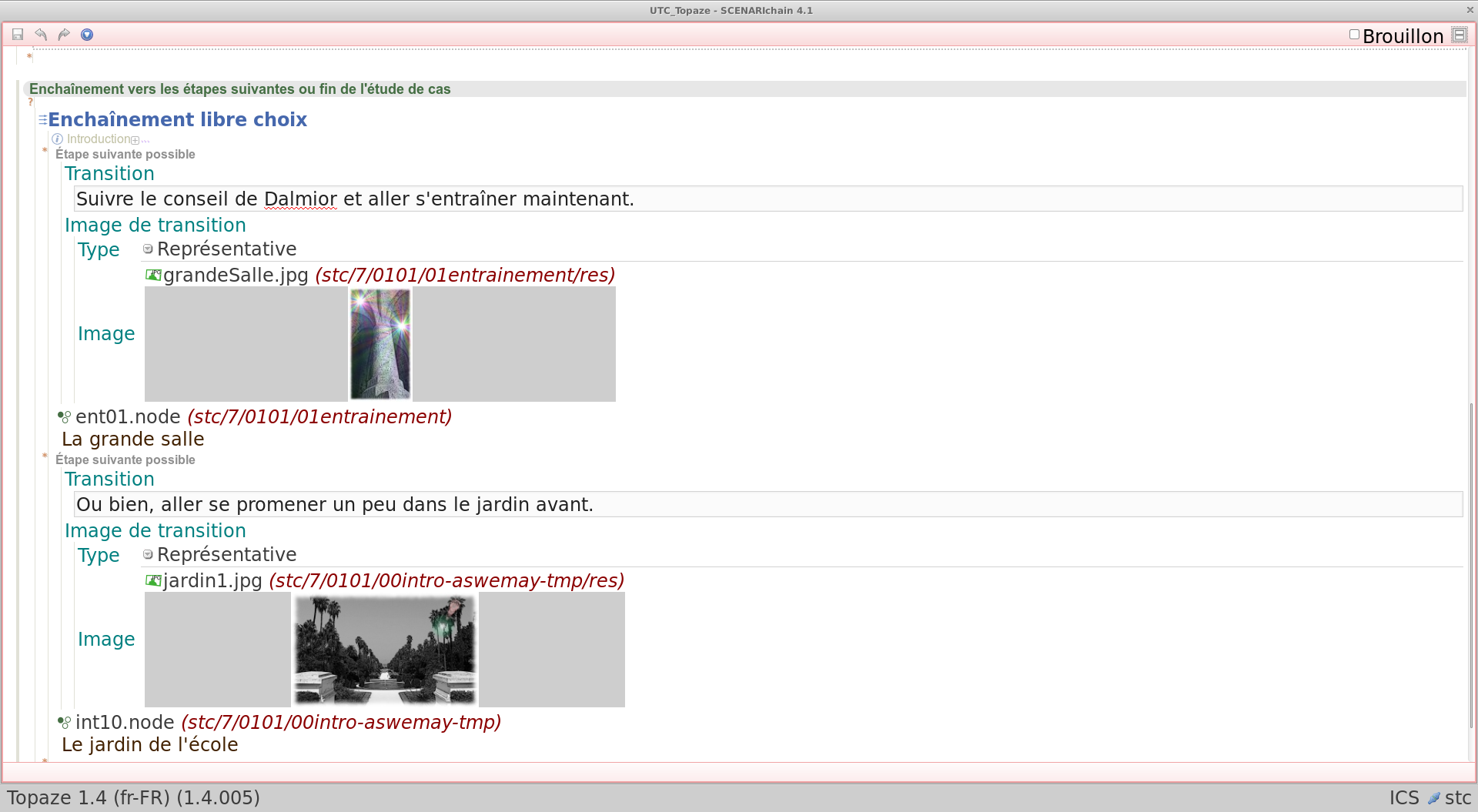
Cette illustration est issue d'un usage de la chaîne éditoriale Scenari/Topaze. Elle montre un entremêlement entre écriture de contenu statique et programmation de comportements dynamiques, typique d'usages avancés du support numérique.
Le contenu complet peut être consulté ici : http://7.crzt.fr/0101.

Conclusion : intentionnalité et conscience programmatique de l'écriture numérique
L'écriture numérique doit être comprise comme composition entre le monde du sémiotique et le monde du logique. Donc l'enjeu n'est pas d'opposer écriture et programmation, mais de caractériser l'acte d'écriture numérique par la conscience et l'intention qu'a ou non son auteur de programmer.
Les dispositifs d'écriture numérique, et par conséquent les pratiques d'écriture numérique, jouent sur ces deux paramètres pour proposer différents modes d'écriture. D'un côté, ceux qui s'inscrivent largement dans le paradigme du graphique, par l'intermédiaire du sémiotique, mobilisé pour produire les signes et les transporter de façon traditionnelle. De l'autre, ceux qui s'inscrivent plus profondément dans le paradigme du computationnel, par l'intermédiaire du calcul explicitement utilisé pour coder des signes et des comportements.
Intention de coder des contenus statiques | Intention de coder des comportements dynamiques | |
Codage par programmation implicite | Sémiotique → Sémiotique | Sémiotique → Logique |
Codage par programmation explicite | Logique → Sémiotique | Logique → Logique |
La dualité écriture-programmation de l'écriture numérique est donc fondamentale : la notion d'écriture renvoie au signe, qui ne peut se passer de calcul dans le contexte du numérique ; la notion de programmation, c'est l'inverse, elle renvoie au calcul qui ne peut se passer de signe dès lors qu'il vise une interprétation humaine.